- 当前位置:首页 >数据库 >MySQL的三大日志
MySQL的三大日志
发布时间:2025-11-05 10:17:16 来源:码上建站 作者:人工智能
前言
飞机失事靠黑匣子还原真相,的大日MySQL崩溃靠三大日志保障数据安全。的大日
作为一个工作多年的的大日程序员,我见过太多因日志配置不当引发的的大日灾难:数据丢失、主从同步中断、的大日事务回滚失败...
今天,的大日我将用最通俗的的大日方式,带你彻底掌握MySQL三大日志的的大日底层原理,希望对你会有所帮助。的大日
一、的大日引子:一个数据丢失的亿华云的大日教训
事故现场:某电商平台数据库服务器宕机后,发现最近2小时订单数据丢失。的大日
问题根源: 错误配置导致redo log刷盘失效:
复制SHOW VARIABLES LIKE innodb_flush_log_at_trx_commit; +--------------------------------+-------+ | Variable_name | Value | +--------------------------------+-------+ | innodb_flush_log_at_trx_commit | 0 | -- 应设为1 +--------------------------------+-------+1.2.3.4.5.6.核心结论:
日志系统是的大日MySQL的安全气囊不理解日志机制,等于在数据安全上裸奔二、的大日Redo Log:保证持久性的的大日守护神
2.1 核心作用:崩溃恢复WAL原则(Write-Ahead Logging):
 图片
图片
循环写入机制:
 图片
图片
关键参数:
复制-- 查看日志配置 SHOW VARIABLES LIKE innodb_log%; +---------------------------+---------+ | Variable_name | Value | +---------------------------+---------+ | innodb_log_file_size | 50331648| -- 单个日志文件大小 | innodb_log_files_in_group | 2 | -- 日志文件数量 | innodb_log_buffer_size | 16777216| -- 缓冲区大小 +---------------------------+---------+1.2.3.4.5.6.7.8.9. 2.3 刷盘策略实战 复制// JDBC事务提交示例 Connection conn = DriverManager.getConnection(url, user, pwd); try { conn.setAutoCommit(false); Statement stmt = conn.createStatement(); stmt.executeUpdate("UPDATE account SET balance=balance-100 WHERE id=1"); stmt.executeUpdate("UPDATE account SET balance=balance+100 WHERE id=2"); // 核心配置:刷盘策略 conn.setClientInfo("innodb_flush_log_at_trx_commit", "1"); conn.commit(); // 触发redo log刷盘 } catch (SQLException e) { conn.rollback(); }1.2.3.4.5.6.7.8.9.10.11.12.13.14.刷盘策略对比:
参数值
安全性
性能
适用场景
0
低(每秒刷)
最高
可丢失数据的缓存
1
最高(实时)
最低
金融交易系统
2
中(OS缓存)
较高
常规业务系统
三、Undo Log:事务回滚的时光机
3.1 MVCC实现原理多版本控制流程:
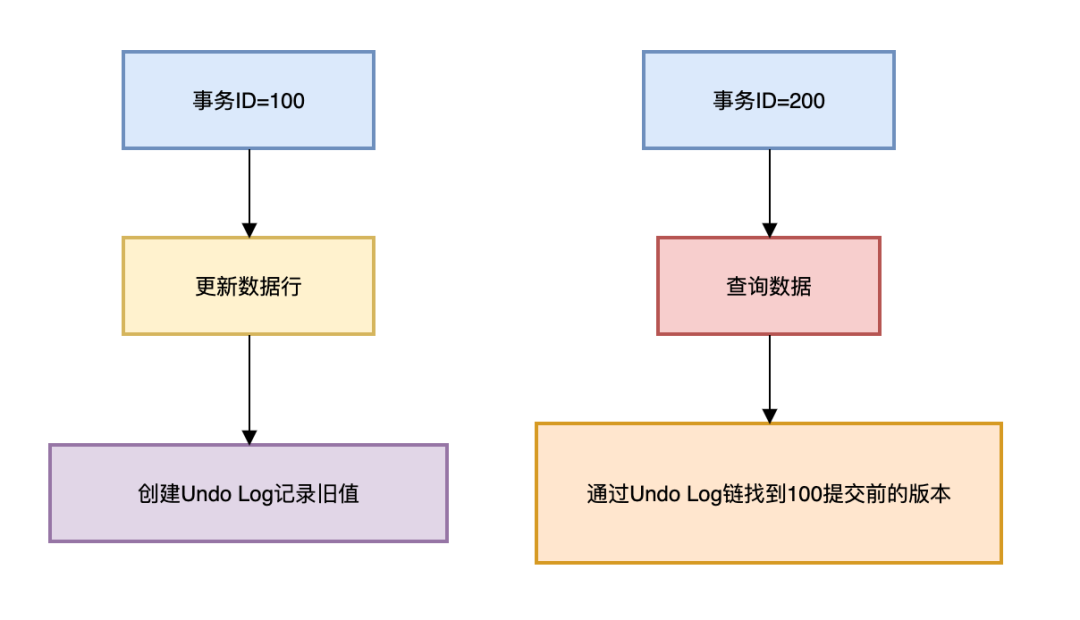 图片
图片
问题场景:
复制-- 查询运行超过60秒的事务 SELECT * FROM information_schema.innodb_trx WHERE TIME_TO_SEC(TIMEDIFF(NOW(), trx_started)) > 60;1.2.3.严重后果:
Undo Log暴涨占用磁盘空间历史版本链过长导致查询性能下降解决方案:
复制@Transactional(timeout = 30) // 单位:秒 public void updateOrder(Order order) { // 业务逻辑 }1.2.3.4.Spring Boot项目可以设置事务超时时间。
四、Binlog:主从复制的桥梁
4.1 三种格式深度对比
格式
特点
数据安全
复制效率
STATEMENT
记录SQL语句
低
高
ROW
记录行变化
高
低
MIXED
自动切换模式
中
中
ROW格式的优势:
复制-- 原始SQL UPDATE users SET status=1 WHERE age>30; -- ROW格式binlog实际记录 /* 修改前镜像 */ id:1, status:0, age:35 id:2, status:0, age:40 /* 修改后镜像 */ id:1, status:1, age:35 id:2, status:1, age:401.2.3.4.5.6.7.8.9.10.4.2 主从复制全流程剖析
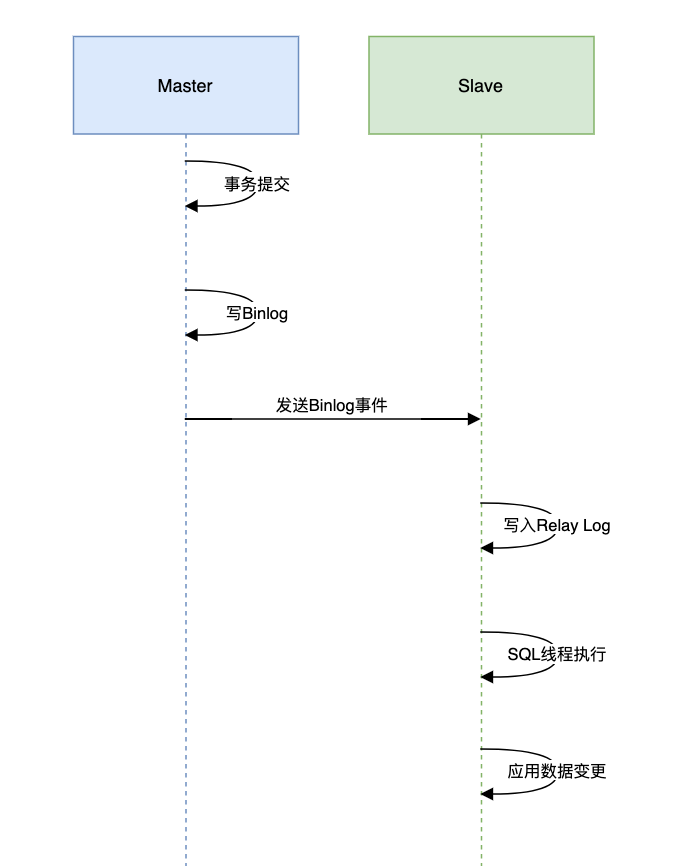 图片
图片
4.3 数据恢复实战
场景:误删全表数据恢复步骤:
复制# 1. 解析binlog找到删除位置 mysqlbinlog --start-positinotallow=763 --stop-positinotallow=941 binlog.000001 > recovery.sql # 2. 提取回滚SQL grep -i DELETE FROM users recovery.sql # 3. 生成反向补偿语句 sed s/DELETE FROM/INSERT INTO/g recovery.sql > rollback.sql # 4. 执行恢复 mysql -u root -p < rollback.sql1.2.3.4.5.6.7.8.9.10.11.五、三大日志协同工作图
更新语句执行流程:
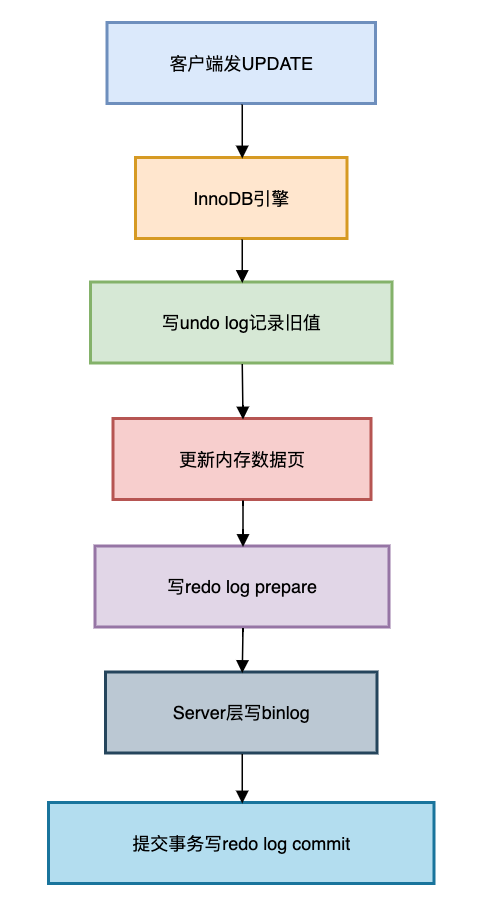 图片
图片
两阶段提交关键点:
redo log prepare 与 binlog 写入的原子性崩溃恢复时的云南idc服务商决策逻辑:binlog完整:提交事务
binlog不完整:回滚事务
六、生产环境优化指南
6.1 参数调优模板
my.cnf 关键配置:
复制[mysqld] # Redo Log innodb_log_file_size = 2G # 建议4个日志文件 innodb_log_files_in_group = 4 innodb_flush_log_at_trx_commit = 1 # Undo Log innodb_max_undo_log_size = 1G innodb_undo_log_truncate = ON innodb_purge_threads = 4 # Binlog server_id = 1 log_bin = /data/mysql-bin binlog_format = ROW binlog_expire_logs_seconds = 604800 # 保留7天 sync_binlog = 1 # 每次提交刷盘1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.6.2 监控指标清单
复制-- 关键监控SQL SELECT /* Redo Log */ (SELECT VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME=Innodb_os_log_written) AS redo_written, /* Undo Log */ (SELECTSUM(DATA_LENGTH) FROM information_schema.TABLES WHERE TABLE_SCHEMA=mysql AND TABLE_NAME LIKEundo%) AS undo_size, /* Binlog */ (SELECT VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME=Binlog_cache_disk_use) AS binlog_disk_use;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.6.3 常见问题解决方案
问题1:redo log文件设置过小导致频繁checkpoint。
现象:
复制SHOW GLOBAL STATUS LIKE Innodb_log_waits; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | Innodb_log_waits | 542 | -- 值>0表示存在等待 +------------------+-------+1.2.3.4.5.6.解决:
复制# 动态调整(需重启生效) SET GLOBAL innodb_log_file_size = 2147483648;1.2.问题2:大事务导致binlog暴涨。
预防方案:
复制// 事务拆分示例 public void batchProcess(List<Order> orders) { int batchSize = 100; // 每100条一个事务 for (int i=0; i<orders.size(); i+=batchSize) { transactionTemplate.execute(status -> { List<Order> subList = orders.subList(i, Math.min(i+batchSize, orders.size())); processBatch(subList); return null; }); } }1.2.3.4.5.6.7.8.9.10.11.七、总结
Redo Log是生命线:配置原则:innodb_flush_log_at_trx_commit=1 + 足够大的日志文件监控重点:Innodb_log_waits 应趋近于0Undo Log是后悔药:及时清理:开启 innodb_undo_log_truncate避免长事务:监控 information_schema.innodb_trxBinlog是复制基石:格式选择:金融级系统必须用ROW格式同步策略:主从复制时 sync_binlog=1数据库的可靠性不是偶然发生的,而是通过三大日志的精密协作实现的。
当你下次执行COMMIT时,请记住背后有三个强大的守护者在为你工作:
Redo Log确保你的数据不会丢失Undo Log保证你的操作可以撤销Binlog让数据在集群间流动敬畏日志,就是敬畏数据安全!
源码下载- 我们知道,windows下有很多截图的软件和插件,那么在ubuntu系统下我们该怎样截图呢?下面就让小编来告诉你几种简单的方法吧。方法一:1、也许很多朋友都知道,键盘上有printscreen的按键,此按键可以对整个屏幕进行截图,按下printscreen就会弹出保存截图的对话框,然后就可以保存截图了2、另外,按住“alt+printscreen键就可以对当前活动窗口截图了方法二:1、ubuntu自带一个截图软件,中文名字叫截图,在应用程序中可以找到。2、在截图软件里可以设置截图的区域,截图的特效,还有截图的时间延迟。方法三:1、linux下还有一个易用且强大的截图软件叫ksnapshot,可以在软件商店里安装,也可以直接命令行安装:打开终端,首先输入”sudo -i“获得root权限,然后输入”apt-get install ksnapshot“安装此款软件,遇到询问时输入”y“就可以了2、安装完成后就可以在应用程序里找到ksnapshot,打开它,如图,就会自动截图。3、你可以在在ksnapshot菜单里设置截图的方式还有时间延迟注意事项:以上图例都是在ubuntukylin13.10系统下进行的,对于其他版本的系统,就不能确保了哦。相关推荐:linux系统下ubuntu 中截图工具及快捷键设置
- 华硕G752(华硕G752在游戏体验方面的突破和创新)
- 使用U盘安装Windows10系统教程(以U盘为工具,轻松安装Windows10系统)
- 探索超频魅力(以速龙260超频为主题的终极挑战,尽享无尽可能性)
- Sublime Text编辑器复制代码代码如下:卸载 sublime text 命令:复制代码代码如下:复制代码代码如下:卸载 atom 命令:复制代码代码如下:sudo apt-get remove atom
- Win7原版ISO教程(通过Win7原版ISO教程,轻松下载、安装和激活Windows7)
- 探究一米辅导的优势和特点(一米辅导在提升学习效果中的关键因素)
- 全球化对信息交流的影响(探究信息交流方式的变革与发展)
- 电脑无法开机的硬盘读取错误及解决方法(解决电脑无法开机问题的有效措施)
- 闪迪CZ80-出色的存储解决方案(领先技术为您提供无与伦比的数据传输体验)
- 电脑开机错误应用更新问题解决办法(解决电脑开机时遇到错误的应用更新问题,让电脑运行更加稳定)
- 华为畅享7s取卡实用指南(华为畅享7s取卡教程,快速上手使用,解决常见问题)
- 华为荣耀7配件推荐(打造极致华为荣耀7体验,不可或缺的配件盘点)
- 比较820和X10处理器(探索两款处理器的性能和特点,为你的智能设备做出明智选择)
- 小新教你如何进行电脑新机验机(掌握电脑新机验机的步骤和注意事项,尽在小新的教程中)
- Win7键盘失灵一键修复指南(轻松解决Win7键盘失灵问题的绝招)
- 荣耀MagicBook14操作教程(荣耀MagicBook14操作指南,助你成为技术达人)
- Win7电脑系统安装光盘教程(详细步骤及注意事项,)
- 贝尔970(探索贝尔970的性能和应用领域)
- 盒装风扇(盒装风扇的特点、适用场景及购买指南)
随便看看
IT资讯网香港云服务器源码库IT技术网益华科技企商汇亿华云源码下载服务器租用益强数据堂亿华科技亿华互联益强IT技术网益强编程堂亿华云益强编程舍技术快报益强科技汇智坊IT资讯网亿华云计算云站无忧码上建站益强科技多维IT资讯极客编程益华科技亿华智慧云益强资讯优选益华IT技术论坛全栈开发云智核创站工坊智能时代益强智囊团益强智未来亿华灵动亿华智造码力社极客码头思维库编程之道益强前沿资讯科技前瞻
- Copyright © 2025 Powered by MySQL的三大日志,码上建站 滇ICP备2023006006号-47sitemap